he previous sections
(
Wavelet calculations
) and
(
Calculation of
approximation spaces
) contain recipes and code for constructing families
of
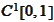 -functions
-functions
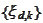 (scaling functions) and
(scaling functions) and
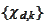 (wavelets) with the following
properties
(wavelets) with the following
properties
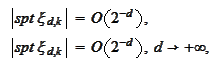
|
|
(Wavelet approximation 1)
|
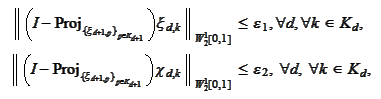
|
|
(Wavelet approximation 2)
|
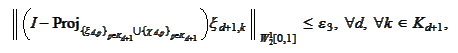
|
|
(Wavelet approximation 3)
|
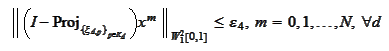
|
|
(Wavelet approximation 4)
|
where
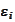 are small constants depending only on the number of steps of the cascade
procedure. The quantities
are small constants depending only on the number of steps of the cascade
procedure. The quantities
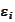 vanish when increasing such number of steps. The sets
vanish when increasing such number of steps. The sets
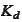 are defined in the section
(
Adapting GMRA to interval
[0,1]
).
are defined in the section
(
Adapting GMRA to interval
[0,1]
).
The calculations were done with plain Python means. This provided some
baseline but imposed restrictions on the amount of calculations that may be
performed in a reasonable time. In this section we upgrade to a Cuda/C++ based
library for polynomial manipulations (see the section
(
Piecewise polynomials in
parallel
)) and derive practical solutions.
We use the previously developed recipes, optimizations and motivations, see
the chapters (
Wavelet
calculations
) and
(
Calculation of
approximation spaces
).
The following remark on the manner of memory allocation on Cuda GPU is
important for understanding of structure of the code. Experimentation with
cudaGetMemInfo reveals that Cuda memory allocation/deallocation acts like
stack. If one allocates blocks A,B,C and then deallocates A and B then the
amount of free memory does not reflect the deallocations. One has to
deallocate the C as well to actually increase the amount of free memory.
Therefore, all permanent data is kept on CPU and only the operational data is
temporarily placed into the GPU memory.
|
